DeepSeek-V3 技术报告精读
概述
DeepSeek-V3 于 2024 年 12 月 27 日由 DeepSeek-AI 发布,是一个基于 MoE((混合专家)架构的大语言模型,融合了 MLA(多头潜在注意力)和 MTP(多 Token 预测)三大核心创新。总参数量 671B,每个 token 仅激活 37B 参数,在 14.8 万亿 tokens 上完成预训练。
整次训练采用 FP8 混合精度,结合 GRPO 强化学习对齐和 SFT 监督微调,仅耗费 2.788M H800 GPU 小时(约 $5.6M),效率惊人。
论文:DeepSeek-V3 Technical Report 代码:github.com/deepseek-ai/DeepSeek-V3
创新点
DeepSeek-V3 的三项关键技术各自解决了大模型不同维度的瓶颈:
架构设计:通过 MLA 和 DeepSeekMoE 架构实现高效的推理和低成本训练。
辅助无损策略:采用了辅助无损策略来实现负载均衡。
**多 token 预测:通过多 token 预测训练目标提高数据效率和模型表现。
FP8 混合精度训练:在极大规模模型上验证了 FP8 训练的有效性,通过支持 FP8 计算和存储,实现加速训练和减少 GPU 内存使用。
一、MLA:Multi-Head Latent Attention
KV Cache 的显存瓶颈
在标准 Transformer 推理中,自回归生成需要缓存所有之前 token 的 Key(K) 和 Value(V)。对于一个 671B 的 MoE 模型,这个开销有非常之大
对于一个标准 KV cache 估算(61 层, 32 头, 128 dim):每 token 缓存元素 = 61 × 32 × 128 = 249,856,每 token 内存占用 ≈ 10.73 GB (FP16),在长上下文(32K tokens)时 ≈ 343 GB,多并发请求时内存爆炸 💥。
这就是 MLA 要解决的核心问题——KV Cache 内存瓶颈。
MLA 的核心思路:低秩压缩
MLA 的洞察很简洁:不需要缓存完整的 K/V 矩阵,而是将它们压缩到一个低维「潜在空间」,需要时再解压缩。
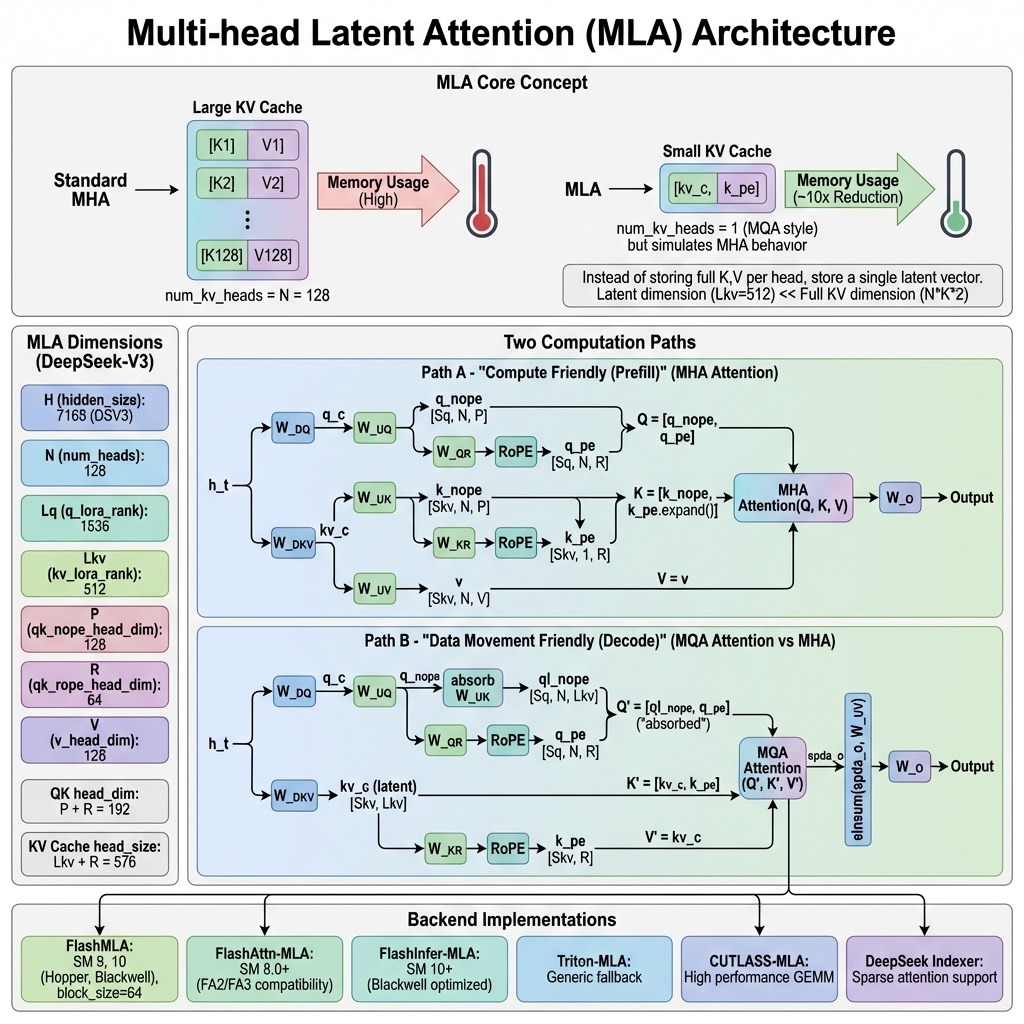
关键技巧——KV 权重吸收(”免费午餐”):
这是 MLA 最巧妙的设计。在注意力计算时,解压缩矩阵可以被”吸收”进 Q 投影矩阵,消除所有解压缩的计算开销:
常规解压缩计算:
Q × K^T = Q × (W_uk × c_KV)^T
= Q × c_KV^T × W_uk^T
= (Q × W_uk^T) × c_KV^T ← W_uk 被吸收进 Q 的权重
结果:解压缩矩阵 W_uk 的乘法被"合并"进 Q 的投影计算中
→ 零额外开销!✨
同样,W_uv 被吸收进输出投影矩阵 W_O。推理时,唯一需要从内存加载的 KV 相关数据是极小的潜在向量 c_KV(512 维)。
这就是 MLA 的”免费午餐”:既享受了 KV 缓存压缩 98.6% 的内存节省,又不增加任何解压缩的计算开销。
效果量化
| 项目 | 标准 MHA | MLA(吸收模式) | 节省 |
|---|---|---|---|
| 每层 KV 缓存 | 10.73 GB | 0.151 GB | 98.6% |
| 每 token 缓存元素 | 49,152 | 576 | ~85× |
| 支持并发请求 | — | 512+ | — |
维度分解详解
MLA将 Q 和 K 分解为两个分量:内容注意力(不含位置编码)和 位置感知注意力(使用 RoPE):
# MLA 核心维度参数
qk_nope_head_dim = 128 # 内容注意力(不含位置编码)
qk_rope_head_dim = 64 # 位置感知注意力(RoPE)
v_head_dim = 128 # Value 维度
kv_lora_rank = 512 # KV 压缩秩
q_lora_rank = 1536 # Q 压缩秩
# Q/K 拼接后的形态
q = [q_nope, q_rope] # 总 192-dim
k = [k_nope, k_rope] # 总 192-dim
这种分解让 MLA 既能通过低秩压缩大幅降低 KV 缓存,又能通过 RoPE 保持位置感知能力,使 DeepSeek-V3 的每 token KV 缓存仅约 70KB(传统方法的 1/4 到 1/7),在 128K 长上下文中推理速度提升 3.2 倍。
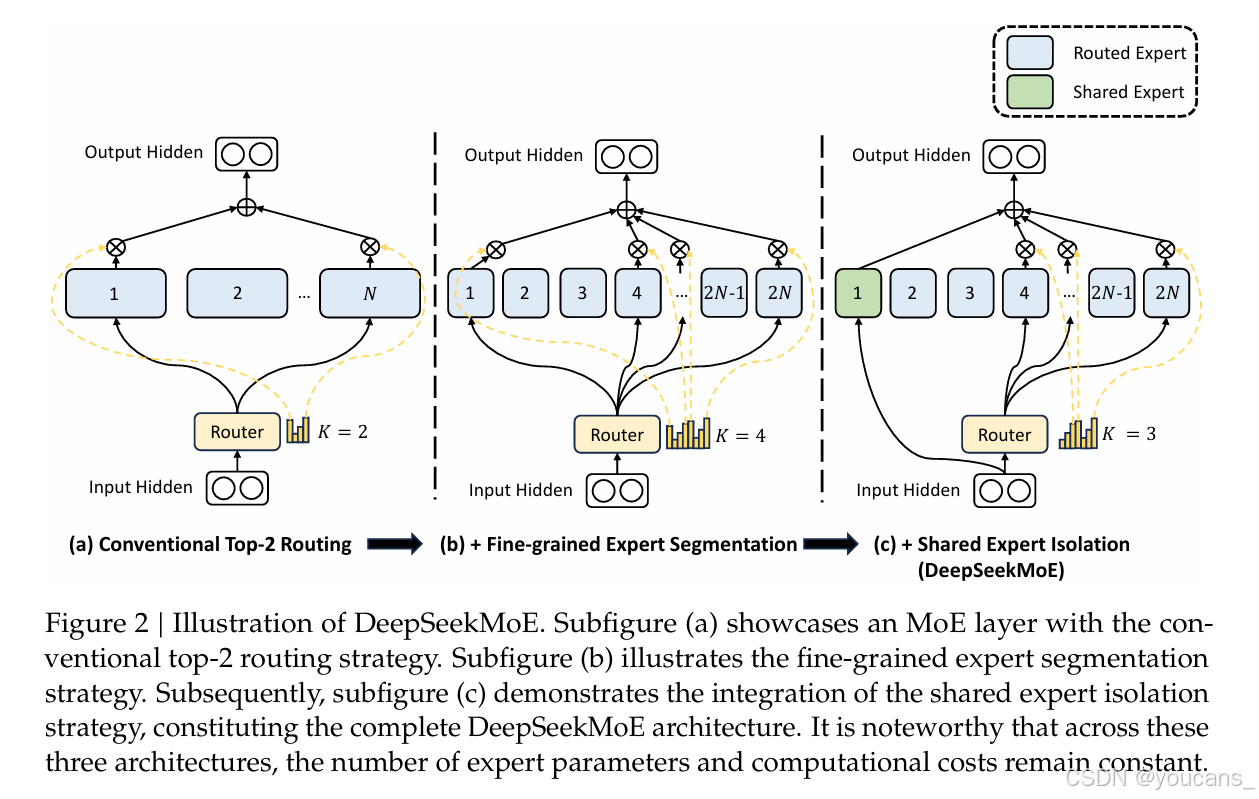
二、DeepSeekMoE 架构
模型配置
DeepSeekMoE 架构的核心思想:将模型分解为多个「专家」子网络,每个 token 仅激活部分专家,在相同计算量下大幅增加模型容量。
DeepSeek-V3 MoE 配置 详情:
总参数量: 671B
每 token 激活37B(5.5%)
路由专家数:256
共享专家:1
每 token 选:8 个专家(Top-8)
分组策略:8 组,每组 32 专家,选 Top-4
总层数:61(前 3 层为 dense)
分组路由机制
DeepSeek-V3 没有使用简单的 Top-8 路由,而是引入了分组路由来提升专家选择效率:
无 Aux Loss 负载均衡
传统 Moe训练中,由于路由机制可能让部分专家过载、部分闲置,通常使用 辅助损失函数(Auxiliary Loss)来平衡专家负载。但额外损失会干扰主任务训练,且需要调节权重超参数 α。
DeepSeek-V3 提出了无辅助损失的动态 bias 调整策略:
传统方式:
Loss = 主任务 Loss + α × Auxiliary Loss
↑ α 需要手动调节,可能干扰主任务
DeepSeek-V3 动态 bias 调整:
对每个专家维护一个 bias 值:
该批次中专家负载 > 平均负载
→ bias -= 0.01 (降低被选概率)
该批次中专家负载 < 平均负载
→ bias += 0.01 (增加被选概率)
专家选择时: score = logit + bias
✅ 完全不需要 Auxiliary Loss!
这种策略的好处:
- 零超参数调节:不需要 α 调参
- 不干扰主任务:没有任何额外损失项
- 自适应:随训练动态调整,适应不同阶段
前 3 层使用 dense 计算(不启用 MoE),保证训练稳定性。
三、MTP:Multi-Token Prediction
从单 Token 到多 Token
传统语言模型训练时,每个位置只预测下一个 token。MTP 创新性地让模型同时预测多个未来 token:
传统方式(仅预测下一个 token):
"我 爱 深 度 学 习"
│ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼
爱 深 度 学 习 <EOS>
MTP 方式(同时预测多个未来 token):
"我 爱 深 度 学 习"
│ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼
预测 1: 爱 深 度 学 习 <EOS> ← 主任务
预测 2: 深 度 学 习 <EOS> ← 辅助任务 1
预测 3: 度 学 习 <EOS> ← 辅助任务 2
MTP 的实现细节
MTP 使用额外的预测头(prediction heads)来实现多步预测,每个预测头共享底层表示但有自己的输出层:
输入序列: [t₁, t₂, t₃, ..., tₙ]
主模型: Transformer 编码 → h₁, h₂, h₃, ..., hₙ
预测头 1(主任务): hₙ → Linear → softmax → 预测 tₙ₊₁
预测头 2(MTP): [hₙ, emb(tₙ₊₁)] → Linear → softmax → 预测 tₙ₊₂
预测头 3(MTP): [hₙ, emb(tₙ₊₁), emb(tₙ₊₂)] → Linear → softmax → 预测 tₙ₊₃
为什么 MTP 有效
由于 MTP 强制模型学习更长距离的依赖关系(主任务只需推理到下一步,辅助任务需要推理到多步以后),模型被迫建立更稳健的长程依赖建模能力。
关键:MTP 在推理时不需要额外开销——只取第一步预测结果,辅助预测头完全丢弃。但训练时获得的收益(更好的长程依赖、更强的表示能力)会保留。
在代码生成和数学推理任务上,启用 MTP 的模型提升显著。
四、训练方法
三阶段训练范式
DeepSeek-V3 的训练分为三个阶段,每个阶段的目标和技术各不相同:
预训练 ──────────────────────────▶ SFT ──────────────────▶ RL
├ 14.8T tokens │ 监督微调 │ GRPO 强化学习
├ 2,048 NVIDIA H800 │ 指令对齐 │ 推理能力提升
├ FP8 混合精度 │ 人工标注数据 │ 无需 Critic 模型
└ 2.788M GPU 小时 │ │ 分组相对策略优化
阶段一:预训练
- 数据规模:14.8 万亿 tokens
- 硬件配置:2,048 块 NVIDIA H800 GPU
- 训练时间:2.788M H800 GPU 小时(约 $5.6M 成本)
- 精度策略:全程 FP8 混合精度训练
- 数据构成:通用文本(1.2T+)+ 代码(300B)+ 150 种平行语料
- 数据清洗:规则过滤 → BERT 语义过滤 → RLHF 对齐多阶段
对比:训练 Llama 3 405B 用了 30.8M GPU 小时,是 DeepSeek-V3 的 11 倍。
阶段二:SFT(监督微调)
预训练后的模型虽然语言能力很强,但缺乏指令遵循能力。SFT 使用人工标注的高质量指令-回答对来微调模型,使其:
- 能够理解并遵循用户指令
- 输出格式符合预期
- 拒绝不当请求
阶段三:GRPO(强化学习对齐)
GRPO 是 DeepSeek 自研的强化学习算法,用于替代传统的 PPO 方法:
PPO(传统强化学习):
Actor(策略模型)──▶ 生成回答 ──▶ Reward Model ──▶ 评分
│ ▲
└────── Critic(价值模型)──────────┘
需要额外维护一个 Critic 模型,显存翻倍
GRPO(DeepSeek 自研):
Actor(策略模型)──▶ 生成多个回答 ──▶ Reward Model ──▶ 评分
│
对组内回答的奖励
进行归一化处理
✅ 不需要 Critic 模型,显存减半
✅ 组内相对比较,训练更稳定
GRPO 的优势:
- 无需 Critic 模型:节省近一半训练显存
- 组内相对比较:对同一 prompt 生成多个回答,以组内相对优劣作为信号
- 训练稳定:避免了 Critic 模型训练不收敛的问题
FP8 混合精度训练
DeepSeek-V3 是首个在超大规模(671B)上成功使用 FP8 训练的模型。FP8 相比 FP16/BF16 进一步减半显存占用。
FP8 精度格式:
E4M3(前向传播用): 4 位指数 + 3 位尾数
→ 最大表示值 ~448,精度较高
→ 用于 forward 中的激活和权重
E5M2(反向传播用): 5 位指数 + 2 位尾数
→ 最大表示值 ~57,344,范围更大
→ 用于 backward 中的梯度(梯度值变化范围大)
块级量化(Block-wise Quantization)——FP8 训练能在 671B 规模保持精度的关键:
传统量化:整个张量共用一个缩放因子
[━━━━━━━━━━━━━━━━━━━━] ← 整个矩阵一个 scale
问题:大值拉高 scale,小值被"压死" → 精度损失大 ❌
DeepSeek-V3 的块级量化:
[━━━━][━━━━][━━━━][━━━━] ← 每 128 元素一组,每组独立 scale
[━━━━][━━━━][━━━━][━━━━]
每组有自己的缩放因子 → 精度损失小 ✅
具体分块策略:
激活(Activations): 按 1 × 128 分块 ← 每行独立缩放
权重(Weights): 按 128 × 128 分块 ← 每个小块独立缩放
梯度(Gradients): 按 128 × 128 分块
累加器(Accumulator): 每 128 个元素后提升到 FP32
量化误差控制: < 0.25% ✅
显存节省:
FP32: 每个参数 32 位 → 671B × 4 字节 = 2.68 TB ❌ 不可行
BF16: 每个参数 16 位 → 671B × 2 字节 = 1.34 TB ⚠️ 勉强
FP8: 每个参数 8 位 → 671B × 1 字节 = 671 GB ✅ 训练可行!
DualPipe:通信-计算完全重叠
在 2,048 块 H800 GPU 上训练 671B 模型,通信开销是最大瓶颈。DualPipe 的解决方案是将反向传播拆分为两个阶段来重叠通信:
传统 1F1B 流水线:
[F1]→[F2]→[F3]→[B3]→[B2]→[B1]
GPU 空闲等待 → 气泡(bubble)占 ~50% 时间 ❌
DualPipe 双向调度:
将反向拆分为 W(权重梯度)和 I(输入梯度):
设备 A: F1 → F2 → F3 → B3_W → B3_I → B2_W → B2_I → B1
设备 B: F1 → F2 → [通信] → F3 → B3_W → B3_I → B2_W → B2_I
↑ All-to-All 通信与 F3 计算重叠!
设备 C: F1 → [通信] → F2 → F3 → B3_W → B3_I → B2_W → B2_I
↑ 通信完全隐藏!
效果:气泡减少 50%,吞吐量提升 20% ✅
节点限制路由:每个 token 最多分发至 4 个节点
→ 减少跨节点 All-to-All 通信量
→ 通信量降低 40%
训练稳定性
DeepSeek-V3 在整个训练过程中实现了零不可恢复的 loss spike,无需任何回滚操作。这在 2.788M GPU 小时的超大规模训练中极为罕见。
五、性能基准
| 基准测试 | DeepSeek-V3 | GPT-4 | Claude 3.5 Sonnet |
|---|---|---|---|
| 文本推理 | 92.1 | 91.8 | — |
| 知识 QA | 88.7 | 87.9 | — |
| MMLU | 开源 SOTA | — | — |
| 数学(AIME) | 🏆 领先 | 可比较 | — |
DeepSeek-V3 在 所有开源模型中全面领先,闭源模型中与 GPT-4 和 Claude 3.5 Sonnet 不相上下。
六、后续演进:DeepSeek-V3.2(2025年12月)
2025 年底,DeepSeek 发布了基于 V3 的重大更新 V3.2:
DSA:DeepSeek Sparse Attention
DSA 是 V3.2 引入的稀疏注意力机制,进一步突破长上下文推理的效率边界:
标准注意力: 每个 token 关注所有 past tokens → O(n²)
DSA 注意力: 两级筛选机制
第一级 — 闪电索引器(Lightning Indexer):
快速粗筛 → 为每个 query 挑选候选 key
第二级 — 细粒度 token 选择:
在候选 key 中做精筛 → 只保留最相关的 k 个
最终复杂度: O(n·k),k << n 🚀
其他 V3.2 亮点
- 可扩展 RL 框架:后训练计算量超过预训练的 10%
- Agent 任务合成管线:85K+ 复杂指令(覆盖代码搜索/通用 agent)
- 竞赛成绩:IMO 2025 金牌(35/42)、IOI 2025 金牌、ICPC 世界总决赛 2025 金牌
- SFT + GRPO 联合调优:监督微调与强化学习的深度融合
对开发者的启示
- MLA 注意力是长上下文推理的关键——在自建架构中考虑低秩 KV 压缩
- 无 Auxiliary Loss 负载均衡是一个实用的 MoE 训练技巧,值得借鉴
- 分组 Top-8 路由在 671B 总参数下只激活 37B,性价比极高
- MTP 实现简单、推理无开销、训练收益明显
- FP8 混合精度在大规模训练中显著降低显存和成本
- GRPO 替代 PPO 省去 Critic 模型,降低强化学习训练门槛