VAE 变分自编码器详解
VAE(Variational Autoencoder)变分自编码器,是生成模型的基石之一
一、生成模型要解决什么问题?
核心问题:学习数据的分布
假设你有 10000 张猫的图片。生成模型的目标是:学完这些图片后,能生成全新的、看起来像猫的图片。
训练集: [🐱₁, 🐱₂, 🐱₃, ..., 🐱₁₀₀₀₀] → 学分布 p(x)
生成: 采样自 p(x) → 得到全新的 🐱 (训练集中没有的)
核心难点:高维空间的稀疏性
图片是高维数据。一张 28×28 的灰度图(MNIST)是 784 维空间中的一个点。要直接学习 $p(x)$ 在 784 维空间的分布,需要指数级的数据量——这被称为维度灾难。
VAE 的思路:先降维再生成
VAE 核心:高维的变量可被用低维变量来表示。如一张图片的Latent Space可以是10~100维的向量,每一个向量可以用基于高斯分布的概率来表示范围。
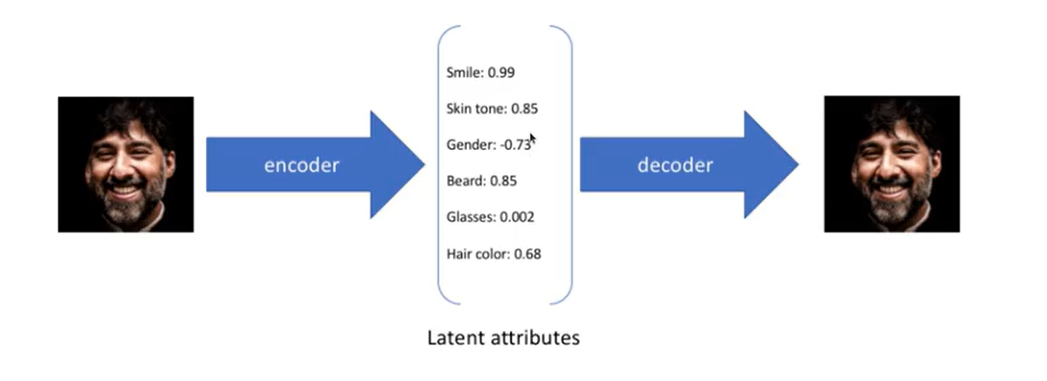
于此,我们可以通过采样潜在变量 $z$ 来生成新的数据空间中的新点,就是通过原图像生成的潜在变量来生成与原图像相关的新的图像。
二、VAE 架构
与普通自编码器的关键区别
普通自编码器(Autoencoder):
输入 x → [编码器] → z(一个固定向量)→ [解码器] → 重建 x̂
问题:z 是"一个点",无法从中采样生成新数据
→ 只能重建见过的数据
VAE:
输入 x → [编码器] → μ, σ²(一个分布的参数)→ 采样 z → [解码器] → 重建 x̂
↓
潜在分布 q(z|x)
优势:z 从分布中采样 → 可以生成无穷多新数据!
即:Autoencoder每次采样是不变的,而VAE每次采样都是随机的,VAE的泛化和潜力巨大。
架构图
编码器(推断网络) 潜在空间 解码器(生成网络)
x ──→ [NN] ──→ μ ─────┐
│ ├──→ z = μ + σ·ε ──→ [NN] ──→ x̂
└──→ σ² ──────┘ ↑
ε ∼ N(0, I) ← 随机噪声
原理解析
如图,为原始的ELBO形式,也是变分推理通用的框架。
 其中公式定义为:
\(\mathcal{L}_q = \mathbb{E}_{z \sim q}[\log p(z, x) - \log q(z)]\)
关键概念:
其中公式定义为:
\(\mathcal{L}_q = \mathbb{E}_{z \sim q}[\log p(z, x) - \log q(z)]\)
关键概念:
-
$q(z) \approx p(z x)$:引入一个近似分布 $q(z)$,来逼近真实后验分布 $p(z x)$(真实后验通常无法直接计算) - $z$:隐变量(Latent Variable),数据的抽象表示
- $x$:观测变量(Observed Variable),输入数据
-
目标:最大化 $\mathcal{L}_q$,等价于让 $q(z)$ 尽可能接近 $p(z x)$,同时提升数据的对数似然 $\log p(x)$
这里补充一下基础:
先验分布 $p(z)$
定义:在观测到数据 $x$ 之前,潜在变量 $z$ 的分布。
常用选择:标准正态分布 $N(0, I)$,即均值为 0、方差为 1 的多维高斯分布。
作用:提供一个规范化的潜在空间,有点像是给出一个模板
后验分布 $q(z|x)$
定义:给定观测数据 $x$ 后,潜在变量 $z$ 的分布。
公式来源(贝叶斯定理):\(p(z|x) = \frac{p(x|z)p(z)}{p(x)}\)
一般来说:后验分布是无法计算的
似然 $p(x|z)$
定义:给定潜在变量 $z$,生成原始数据 $x$ 的概率。
| 于是,公式的目的就是:**引入一个近似分布 $q(z)$,来逼近真实后验分布 $p(z | x)$** |
VAE的改造:引入编码器和解码器
引入编码器和解码器后,分布将参数化。
-
近似分布不再是固定 $q(z)$ 而是条件分布 $q(z x)$,由编码器网络参数化 -
生成数据 $p(x z)$ 由解码器网络参数化
于是公式:
\(\begin{aligned}
\mathcal{L}_q &= \mathbb{E}_{z \sim q}\left[ \log p_\theta(x \mid z)p(z) - \log q_\phi(z \mid x) \right] \\
&= \mathbb{E}_{z \sim q}\left[ \log p_\theta(x \mid z) + \log p(z) - \log q_\phi(z \mid x) \right]
\end{aligned}\)
这个拆分对于了VAE损失函数的两大部分:
-
重构损失:$\mathbb{E}_{z \sim q(z x)}[\log p(x z)]$,衡量生成数据与原始数据的相似度 -
KL 散度:$D_{\text{KL}}(q(z x) | p(z))$,衡量 $q(z x)$ 的分布与 $p(z)$ 的分布的相似度
三、损失函数
VAE 的损失由两部分组成:重构损失 + KL 散度。
1. 重构损失(Reconstruction Loss)
让生成的图片和原图尽可能相似:
\[\mathcal{L}_{\text{recon}} = -\mathbb{E}_{z \sim q(z|x)}[\log p(x|z)]\]直观理解:给定潜在变量 $z$,生成原始数据 $x$ 的概率有多大?概率越大,损失越小。
对于图像,常用二值交叉熵(BCE):
recon_loss = F.binary_cross_entropy(recon_x, x, reduction='sum')
# 每个像素的交叉熵之和
2. KL Divergence 正则化
| 强制 $q(z | x)$ 接近标准正态分布 $N(0, I)$: |
对于两个高斯分布,有闭合解:
\[D_{\text{KL}} = -\frac{1}{2} \sum_{j=1}^{J} \left(1 + \log \sigma_j^2 - \mu_j^2 - \sigma_j^2\right)\]kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
KL 散度的作用:
KL 散度大 → q(z|x) 偏离 N(0, I) 太远
→ 潜在空间结构不好 → 采样出来的 z 没意义 ❌
KL 散度小 → q(z|x) 接近 N(0, I)
→ 潜在空间规整 → 可以从 N(0, I) 采样生成 ✅
但 KL 散度太小也不行 → 会忽略 x 的信息 → 重建效果差
3. 总损失:两个目标的平衡
\[\mathcal{L} = \underbrace{-\mathbb{E}_{z \sim q(z|x)}[\log p(x|z)]}_{\text{重构损失(逼真性)}} + \underbrace{D_{\text{KL}}(q(z|x) \| p(z))}_{\text{KL 散度(可生成性)}}\]平衡关系:
重构损失小 → 重建质量高 → 但可能过拟合(只会复制)
KL 散度小 → 潜在空间规整 → 但可能忽略 x 的信息
好的 VAE → 两者平衡 → 既能重建又能生成
四、Reparameterization Trick:为什么需要它
问题:采样不可微
VAE 训练中最棘手的障碍:
编码器 → μ ──┐
├──→ z ∼ N(μ, σ²) → 解码器
编码器 → σ² ─┘
↑
采样操作!梯度无法反向传播 ❌
解决方法
Reparameterization Trick 把随机采样拆成两步:确定性变换 + 独立噪声。
\[z = \mu + \sigma \cdot \varepsilon, \quad \varepsilon \sim \mathcal{N}(0, I)\]原来(不可微):
z = sample_from(N(μ, σ²)) ← 采样操作无梯度 ❌
现在(可微):
z = μ + σ × ε ← 纯代数运算 ✅
↑ ↑
可微 ε ∼ N(0,I) 独立于模型参数
为什么可行?
因为 $\varepsilon$ 是与模型参数无关的随机噪声,$\mu$ 和 $\sigma$ 是由编码器输出的确定性函数。梯度可以沿 $\mu$ 和 $\sigma$ 回传到编码器。
def reparameterize(self, mu, logvar):
"""重参数化技巧"""
std = torch.exp(0.5 * logvar) # 标准差 σ
eps = torch.randn_like(std) # 独立噪声 ε ∼ N(0, I)
z = mu + eps * std # z = μ + σ × ε
return z
五、完整代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_dim=784, latent_dim=20):
super().__init__()
# === 编码器 ===
self.encoder = nn.Sequential(
nn.Linear(input_dim, 400),
nn.ReLU()
)
self.mu_layer = nn.Linear(400, latent_dim) # 均值
self.logvar_layer = nn.Linear(400, latent_dim) # 对数方差
# === 解码器 ===
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 400),
nn.ReLU(),
nn.Linear(400, input_dim),
nn.Sigmoid() # 确保输出在 [0, 1] 范围
)
def encode(self, x):
h = self.encoder(x)
return self.mu_layer(h), self.logvar_layer(h)
def reparameterize(self, mu, logvar):
# z = μ + σ × ε, ε ∼ N(0,I)
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x) # 编码 → 分布参数
z = self.reparameterize(mu, logvar) # 重参数化采样
recon = self.decode(z) # 解码重建
return recon, mu, logvar
def vae_loss(recon_x, x, mu, logvar):
"""VAE 损失函数"""
# 重构损失:二值交叉熵
recon_loss = F.binary_cross_entropy(
recon_x, x, reduction='sum'
)
# KL 散度:闭合解
# D_KL = -0.5 * Σ(1 + log(σ²) - μ² - σ²)
kl_loss = -0.5 * torch.sum(
1 + logvar - mu.pow(2) - logvar.exp()
)
return recon_loss + kl_loss
六、训练循环
# 超参数
input_dim = 784 # 28×28 图片展平
latent_dim = 20 # 潜在空间维度
batch_size = 128
lr = 1e-3
num_epochs = 50
# 初始化
model = VAE(input_dim, latent_dim)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 训练
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.view(-1, input_dim) # 展平图片
optimizer.zero_grad()
# 前向传播
recon_batch, mu, logvar = model(data)
# 计算损失
loss = vae_loss(recon_batch, data, mu, logvar)
# 反向传播
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader.dataset)
print(f'Epoch {epoch:3d} | 平均损失: {avg_loss:.2f}')
七、生成新数据
训练完成后,生成新数据只需解码器部分:
def generate(model, num_samples=16, latent_dim=20):
"""从标准正态分布采样,生成新数据"""
model.eval()
with torch.no_grad():
# 从 N(0, I) 采样
z = torch.randn(num_samples, latent_dim)
# 解码生成
samples = model.decode(z)
return samples
潜在空间的插值
VAE 最强大的特性之一:平滑插值。
z₁ = encode("猫 A") → 猫 A 的潜在表示
z₂ = encode("猫 B") → 猫 B 的潜在表示
z_α = (1-α) × z₁ + α × z₂ → 中间的潜在表示
α = 0: 猫 A
α = 0.25: 偏 A 的中间猫
α = 0.5: 猫 A 和猫 B 的平均
α = 0.75: 偏 B 的中间猫
α = 1: 猫 B
这是因为 KL 散度强制潜在空间连续且规整——邻近的点对应语义相似的内容。
八、一些个人的思考和一些问题
1. 为什么不能直接不要编码器,直接随机取隐变量呢?
首先,每一个输入的图片在隐变量空间都有一个对应的表示,这个表示是根据图片的内容特征提取的,但是隐变量空间的输入对应的点是有限的,那随机取必然存在噪声。
VAE想到的解决办法则是将每一个隐变量都看作是一个标准正态分布,然后从这个分布中采样,而且各个变量独立。但是如此仍然存在噪声,所以每一个变量都需要尽量的去接近一个均值为0的正态分布。
2. 如何让编码器神经网络生成一个正态分布?
实际上就是让编码器生成正态分布的两个参数,均值和方差。方差必须为正数,神经网络输入为α,用exp(α)来表示方差。所以α = log(方差)
3. 符号定义
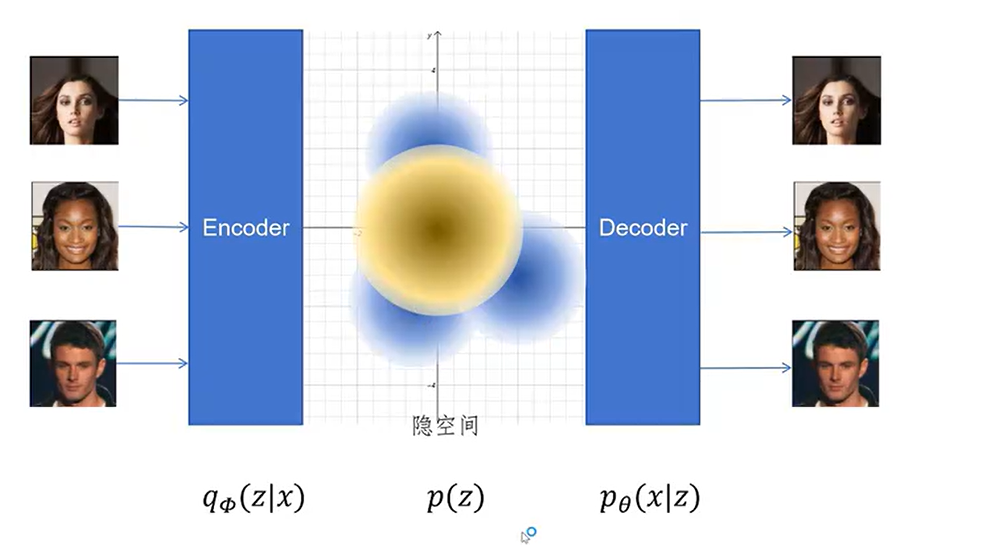 如图,输入的照片是x,encoder是一个映射,它将x映射到隐空间z,$q(z|x)$表示给定一个x,encoder将x映射到不同z的概率密度函数
如图,输入的照片是x,encoder是一个映射,它将x映射到隐空间z,$q(z|x)$表示给定一个x,encoder将x映射到不同z的概率密度函数
$p(z)$表示我们所期望的隐变量z的分布,我们期望z是一个标准的多元正态分布
$q(x|z)$表示给定一个z,解码器将z映射到不同x的概率密度函数,这个也是一个正态分布
最后的Decoder直接输出最后的概率密度函数的均值作为输出的x
4.如何解决VAE的随机性对方向传播计算的影响
传统自编码器其实就是一个神经网络,通过计算输入图片与输出图片MSE即可
但是对于VAE,中间存在一个采样的过程,此时我们似乎无法计算梯度,反向传播似乎中断了
这里我们为了解决这个问题,引入了一个重参数化技巧
即$z = \mu + \sigma \times \epsilon,\ \epsilon \sim \mathcal{N}(0,I)$
确定性函数:$z = \mu + \sigma \times \epsilon$
独立噪声:$\epsilon \sim \mathcal{N}(0,I)$
结合后:$z = \mu + \sigma \times \epsilon,\ \epsilon \sim \mathcal{N}(0,I)$
这样就将随机采样拆成了两步:一个是确定性变换,另一个是独立噪声,z对μ和σ是确定的,可导的函数(这里需要注意,我们把随机采样的随机性放在了ε中)
5. 如何保证z的分布是标准的多元正态分布
这里通过的是KL散度来实现的,即$KL(D_{z|\mu,\sigma} \parallel D_{z|\mu,\sigma}) = -0.5 \times \Sigma(1 + \log(\sigma^2) - \mu^2 - \sigma^2)$ 把KL散度作为VAE的损失函数的一部分,让每一个照片生成的隐变量z的分布都与隐空间的标准多元正态分布一致 故最后的LOSS由两部分组成:一个是重构损失,一个是KL散度损失
6.两个损失是相互制衡的
一方面:重构损失让生成的图像尽可能与原图像相同,此时则需要隐空间内不同的输入图片尽可能的远 另一方面:KL散度损失让隐空间内不同的输入图片尽可能的近来保证输入图像的分布尽可能是标准的多元正态分布
这里推荐一个讲的很好的视频: https://www.bilibili.com/video/BV1TJE8zoEJa/?spm_id_from=333.337.search-card.all.click https://www.bilibili.com/video/BV1Ns4y1J7tK/?share_source=copy_web&vd_source=9ddae8a660784d5c8d074cccde4334d6 最好的算法讲解:https://www.bilibili.com/video/BV1xFxMz1EMS/?share_source=copy_web&vd_source=9ddae8a660784d5c8d074cccde4334d6