Attention
Attention(注意力机制)是一种让模型在处理每个位置时动态关注输入序列中其他位置的机制。
QKV 计算流程可视化
输入序列: [x₁, x₂, x₃, x₄]
Step 1: 计算 Q、K、V(通过线性投影)
x₁ → Q₁, K₁, V₁
x₂ → Q₂, K₂, V₂
x₃ → Q₃, K₃, V₃
x₄ → Q₄, K₄, V₄
Step 2: Q × K^T 计算相似度矩阵
K₁ K₂ K₃ K₄
Q₁ [0.9, 0.1, 0.3, 0.2] ← x₁ 对各个位置的关注度
Q₂ [0.2, 0.8, 0.1, 0.4]
Q₃ [0.3, 0.2, 0.7, 0.1]
Q₄ [0.1, 0.3, 0.2, 0.9]
Step 3: 除以 √d_k 缩放 + Softmax 归一化(每行和为 1)
[0.5, 0.1, 0.2, 0.2] ← 概率分布
[0.1, 0.6, 0.1, 0.2]
[0.2, 0.1, 0.5, 0.2]
[0.1, 0.2, 0.1, 0.6]
Step 4: × V 加权求和得到最终输出
输出₁ = 0.5V₁ + 0.1V₂ + 0.2V₃ + 0.2V₄
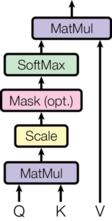
核心计算
Attention(Q, K, V) = softmax(QK^T / √d_k) × V
Q (Query): 当前位置的查询向量
K (Key): 所有位置的键向量
V (Value): 所有位置的值向量
d_k: 缩放因子,防止内积过大
为什么需要 Attention
传统序列模型(RNN)只能顺序处理,长距离信息需要通过多个时间步传递,容易丢失。Attention 让模型一步到位建立任意两个位置之间的直接连接。
Scaled Dot-Product Attention
这是最常用的注意力实现方式:
- 计算 Q 和 K 的点积 → 相似度分数
- 除以 √d_k 缩放 → 防止 softmax 梯度过小
- softmax 归一化 → 注意力权重
- 加权求和 V → 输出