MLA
MLA(Multi-Head Latent Attention,多头潜在注意力)
KV联合低秩压缩+潜在隐向量缓存+按需解压,做到「推理只存低维隐向量、计算还原完整多头K/V」,KV Cache最高压缩93%+,精度逼近原生MHA,超长上下文标配注意力架构。
一、诞生背景:MHA→MQA→GQA→MLA演进逻辑
前代方案痛点
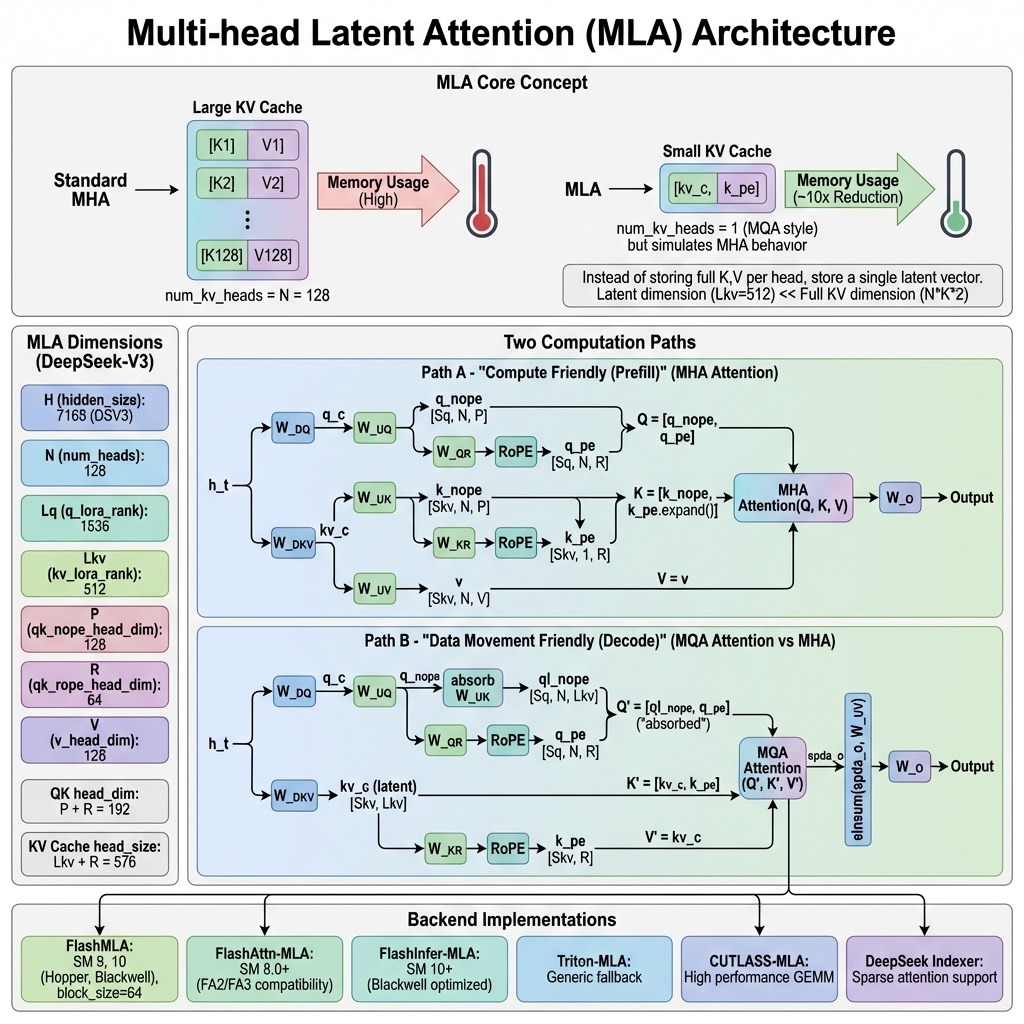
- MHA(原生多头):H个head各存独立K/V,KV Cache显存=O(H·d),超长上下文(128K+)显存爆炸、推理速度极慢;
- MQA:全Head共用1组K/V,缓存O(d),压缩最强,但精度掉点严重;
- GQA:Q分为H头、K/V分为G组共享,缓存O(G·d)(常用G=H/8),工业主流,但压缩上限被分组约束,没法进一步大幅降显存。
MLA核心革新思路
利用多头K/V天然低秩冗余,把全部多头K/V信息压缩进1个低维隐向量$c^{KV}$,推理只缓存$c^{KV}$,计算注意力时再上投影还原全量多头K/V,实现:存储≈MQA大小,计算≈MHA精度。
二、三大核心阶段
1. 压缩阶段(Down-projection:训练时生成隐向量)
输入隐藏层特征$h_t\in\mathbb R^d$(d为模型隐藏维度) \(\boldsymbol c_t^{KV}=h_t\cdot W_{DKV}\)
- $W_{DKV}\in\mathbb R^{d\times d_c}$:联合压缩矩阵,$d_c\ll H\cdot d_h$($d_c$=隐向量维度,远小于全部多头K/V总维度);
- $\boldsymbol c_t^{KV}$:潜在隐向量(Latent Vector),承载所有Head的K/V全部信息;
关键:不再分头生成K/V,先统一压缩成一条短向量。
2. 缓存阶段
KV Cache只保存低维$\boldsymbol c_t^{KV}$,彻底抛弃原始多头K/V
- MHA:单Token缓存=$H\times(d_k+d_v)$
- MLA:单Token缓存=$d_c$($d_c$通常为原生1/8~1/32,显存下降70%~97%)
3. 解压重建阶段(Up-projection:注意力计算前还原多头K/V)
用两套独立可学习上投影矩阵,从同一个隐向量还原每个head独立K、V: \(k_t^{(h)}=\boldsymbol c_t^{KV}\cdot W_{UK}^{(h)},\quad v_t^{(h)}=\boldsymbol c_t^{KV}\cdot W_{UV}^{(h)}\) $W_{UK}^{(h)}/W_{UV}^{(h)}$:第h个注意力头专属升维矩阵,每个头仍然拥有独立K/V,保留MHA多头表征能力。
还原后照常执行标准多头Attention:$Attn(Q^{(h)},k_t^{(h)},v_t^{(h)})$
三、关键难点:RoPE旋转位置编码拆分
RoPE不能被低秩压缩(位置信息逐维绑定),MLA做Q/K二分拆分设计:
- Q拆分两部分
- $Q_{nope}$:无位置信息,跟随隐向量低秩压缩;
- $Q_{rope}$:带RoPE位置编码,单独小维度投影、独立加RoPE;
- K拆分两部分
- $K_{nope}$:从隐向量上投影还原;
- $K_{rope}$:和$Q_{rope}$同维度,单独存储、加RoPE;
最终:只有极小部分rope-K单独缓存,绝大部分KV信息仍压缩在隐向量,兼顾位置精度与压缩率(DeepSeek默认:rope维度=0.5×head_dim)。
四、MHA/MQA/GQA/MLA四项指标横向对比
|指标|MHA|MQA|GQA|MLA| | —- | —- | —- | —- | —- | |KV缓存复杂度|$O(Hd)$|$O(d)$|$O(Gd)$|$O(d_c),d_c\ll d$| |缓存压缩率|基准×1|×1/H|×G/H|×$d_c/(Hd_h)$(最高1/64)| |表达能力|最优|差|良好|≈MHA(几乎无损)| |额外计算开销|0|0|0|少量上下投影(<5%)| |超长上下文适配|差|一般|中等|极佳(128K/256K首选)|
注:H=总头数,G=GQA分组数,$d_h$单头维度,$d_c$MLA隐向量维度
五、MLA两大核心优缺点
✅ 优势
- 极致显存节省:DeepSeek-V2配置下KV Cache降低93.3%,同等显存可开8~30倍上下文长度,推理吞吐提升5~6倍;
- 精度无损:计算时完整还原多头K/V,效果对标原生MHA,远优于MQA/GQA压缩带来的性能损耗;
- 天然适配MoE:DeepSeek标配「MLA+MoE」组合,专家拆分+注意力显存双优化,千亿参数长文本模型最优路线;
- 向下兼容:数学上GQA、MQA均可等价转化为MLA,现有GQA模型可微调迁移MLA。
❌ 缺点
- 训练额外算力:新增上下投影矩阵,训练阶段FLOPs小幅上涨(3%~8%);
- 实现复杂:RoPE拆分、矩阵吸收优化需要定制算子,无法直接套用原生Attention实现;
- 小短文本收益有限:上下文<4K时,KV Cache本身不大,MLA压缩优势不明显。
六、矩阵吸收(Matrix Absorption)
预训练阶段把Q投影矩阵和上投影矩阵提前融合吸收,推理时合并矩阵乘法: \(Q\cdot W_Q \cdot W_{UK}\Rightarrow Q\cdot W_{merge}\) 把两次矩阵乘合并为一次,抹平MLA额外计算开销,推理速度追平GQA(DeepSeek工程落地关键)。