MoE
MoE(Mixture of Experts,混合专家模型)
稀疏条件计算架构,把Transformer里的FFN拆成一堆专精小网络(专家),靠路由动态选少量专家运算,实现「总参数暴涨、单次算力基本不变」,是超大模型主流扩容方案。
一、发展简史
- 1991年:Jacobs、Hinton等人提出初代MoE,用于传统机器学习集成学习,单样本分配单个专家。
- 2017后Transformer时代:2020《Switch Transformer》、GShard把MoE落地进Transformer,替换FFN,Top-K稀疏路由成为现代MoE标准。
- 现行业落地:Mixtral、GPT4、DeepSeek、GLaM、Grok全部采用MoE,千亿/万亿参数大模型标配架构。
二、三大核心组件(标准MoE层)
1. Experts 专家网络
- 本质:多个独立小型FFN(Linear-GELU-Linear),替代原来Transformer单个巨型全连接层。
- 特点:训练中自动专精不同数据分布:语法、数学、代码、常识、多模态各占部分专家。
- 配置:常见每层8/16/32/64个专家,总参数量=专家数×单个专家参数。
2. Router/Gate 门控路由网络(调度中心)
- 结构:极轻量单层线性网络+Softmax,参数量远小于专家。
- 功能:输入单个Token向量 → 输出该Token对所有专家的匹配分数,分数代表适配度。 \(G(x)=\text{Softmax}(x\cdot W_{gate})\)
3. Top-K稀疏选择(MoE灵魂:稀疏激活)
工业通用Top-1/Top-2(最常用Top-2):
- 路由打分后,只保留得分最高的K个专家;
- 其余所有专家完全不参与计算、无FLOPs开销(稀疏核心);
- 被选中专家独立前向运算,最后按Gate权重加权求和得到输出:
\(y=\sum_{选中的i}g_i(x)\cdot f_i(x)\)
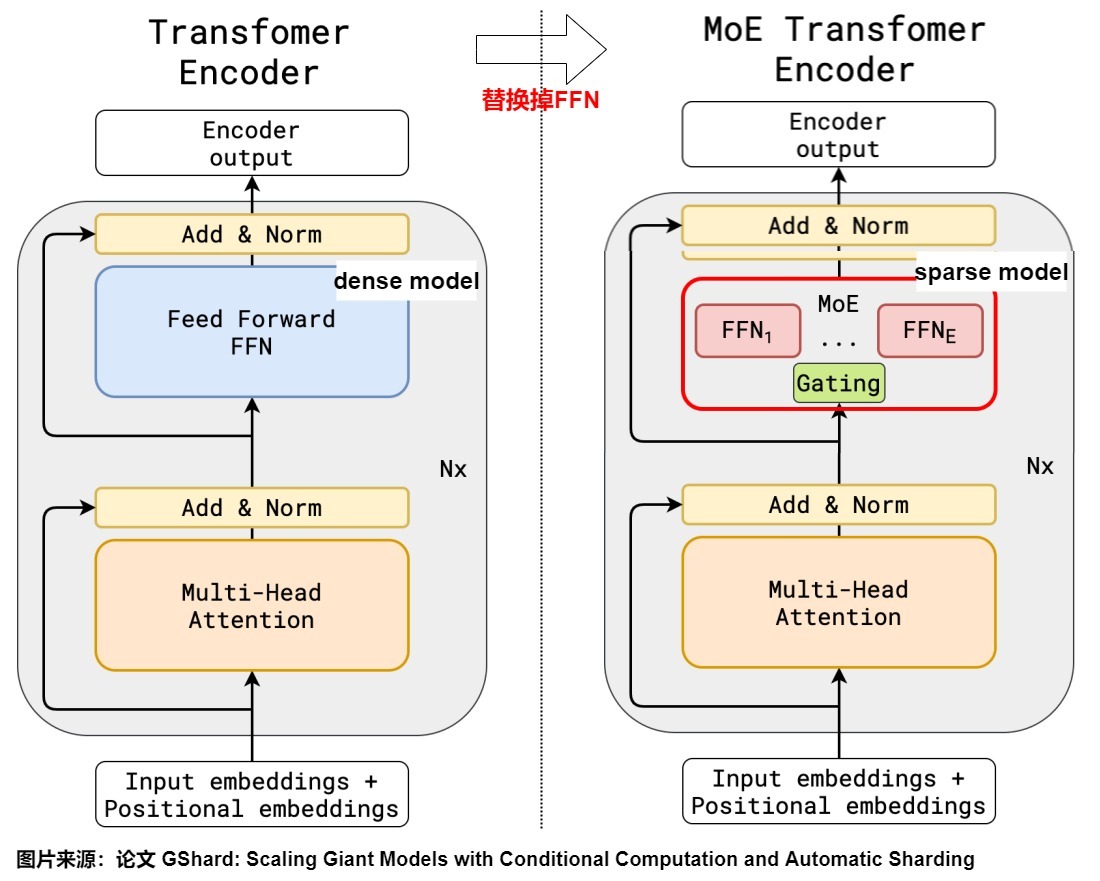
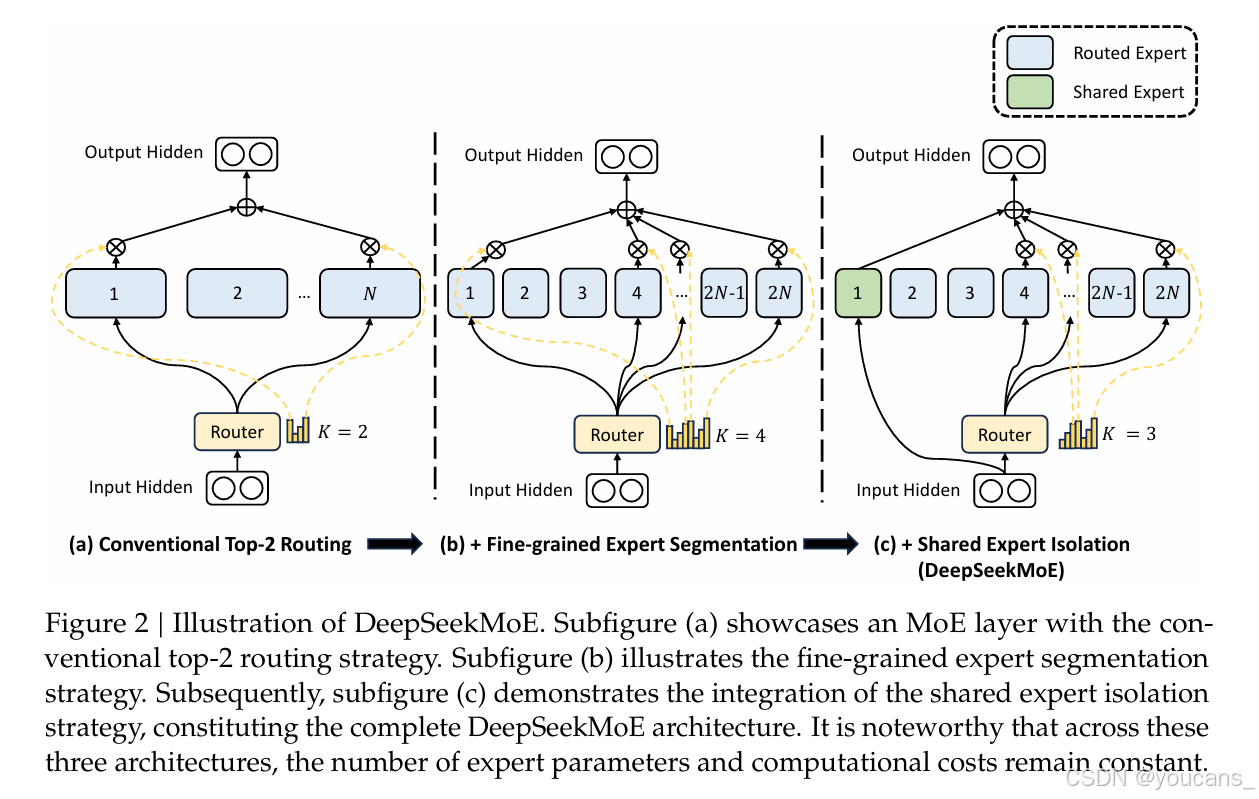
三、完整前向流程(单个Token经过MoE)
- 输入:Attention层输出的Token特征向量;
- 路由打分:轻量Gate计算所有专家匹配概率;
- 稀疏筛选:Top-2保留2个专家,其余冻结不计算;
- 专家推理:选中2个FFN分别运算;
- 加权融合:用Gate权重合并两个专家结果,作为MoE层输出。
举例:16专家+Top2 → 总参数=16倍单FFN,但单次算力≈2倍单FFN,参数和算力彻底解耦。
四、MoE核心优缺点
✅ 优势
- 超大参数低成本扩容:稠密模型参数翻倍算力翻倍;MoE专家翻倍算力只小幅上涨,轻松堆万亿参数。
- 专业化表征更强:专家各司其职,细分知识,复杂任务(数学、代码、多轮)效果显著优于同算力稠密模型。
- 分布式友好:多专家可拆分到不同GPU,大集群并行训练效率高(GShard分布式MoE)。
❌ 痛点(MoE三大工程难题)
- 专家负载不均衡(路由倾斜):部分专家被大量Token选中、部分闲置(冷门专家几乎不激活),算力浪费+训练不稳定。
- 优化:路由加噪声、容量约束、负载均衡损失(Switch Loss)、专家动态扩容。
- 推理低效:稠密模型固定计算链路;MoE动态选专家,访存/调度开销高,小批量推理延迟高于稠密。
- 优化:预路由、专家固化、推理时合并冷门专家。
- 训练不稳定:稀疏梯度带来震荡,需要专属优化器与正则。
五、主流MoE变体对比
| 模型 | 路由规则 | 特点 |
|---|---|---|
| Switch Transformer | Top1 | 极简,单专家,易负载失衡 |
| GShard | Top2 | 工业标杆,双专家,均衡性好(GPT4同源思路) |
| Mixtral MoE | Top2+8专家 | 开源标杆,7B稠密等效47B参数量,低成本 |
| DeepSeek MoE | 动态容量+分组路由 | 自研负载均衡,长文本优化 |
六、常见模型的MoE参数
| 模型 | 总参数量 | MoE专家数 | 每层激活专家数 | 备注 |
|---|---|---|---|---|
| GPT-4 | 1.5T | 128 | 2 | 公开参数 |
| GLaM | 1.2T | 64 | 2 | Google MoE旗舰 |
| DeepSeek-V3 | 671B | 256 | 8(分组路由) | 自研分组路由,长文本优化 |