MTP
MTP(Multi-Token Prediction)
MTP是在主干Transformer尾部串联多层轻量预测模块,训练同时预测$t+1、t+2…t+n$连续多Token;训练端稠密监督提升推理/长文本能力,推理端原生充当Speculative Decoding(投机解码)草稿模型,单次主模型前向校验多Token,生成提速1.8~3倍,DeepSeek-V3/R1、Gemma4、Qwen3标配,常和MLA搭配使用。
一、诞生背景:传统NTP问题
传统LLM仅做Next-Token Prediction(NTP,只预测下1个token):
- 训练缺陷
- 监督信号极度稀疏,每个隐状态只优化1个标签,模型养成「走一步看一步」短视;数学、代码、长文容易逻辑断层、前后矛盾、长距离依赖弱;
- 训练数据利用率低,收敛慢、样本效率差。
- 推理缺陷 自回归逐一生成1个token→更新KV→再生成,串行解码GPU空转,长文本吞吐极低、延迟高。
MTP从训练目标+推理加速双维度同时优化,分为Meta并行多头MTP、DeepSeek级联因果MTP两大主流实现路线。
二、两大MTP架构范式
范式1:Meta原版MTP
- 结构:共用同一个Transformer主干,主干输出后并行挂载$N$个独立输出头,Head1预测$t+1$、Head2预测$t+2$…HeadN预测$t+N$,各头参数独立、预测互不依赖;
- 训练:主损失(NTP)+N个辅助CE损失加权求和一起反向传播;
- 优缺点 ✅实现简单、并行度极高,推理草稿生成极快; ❌各token独立预测,无因果依赖,多头预测序列容易语义断裂、上下文不连贯,草稿token校验通过率偏低(70%左右)。
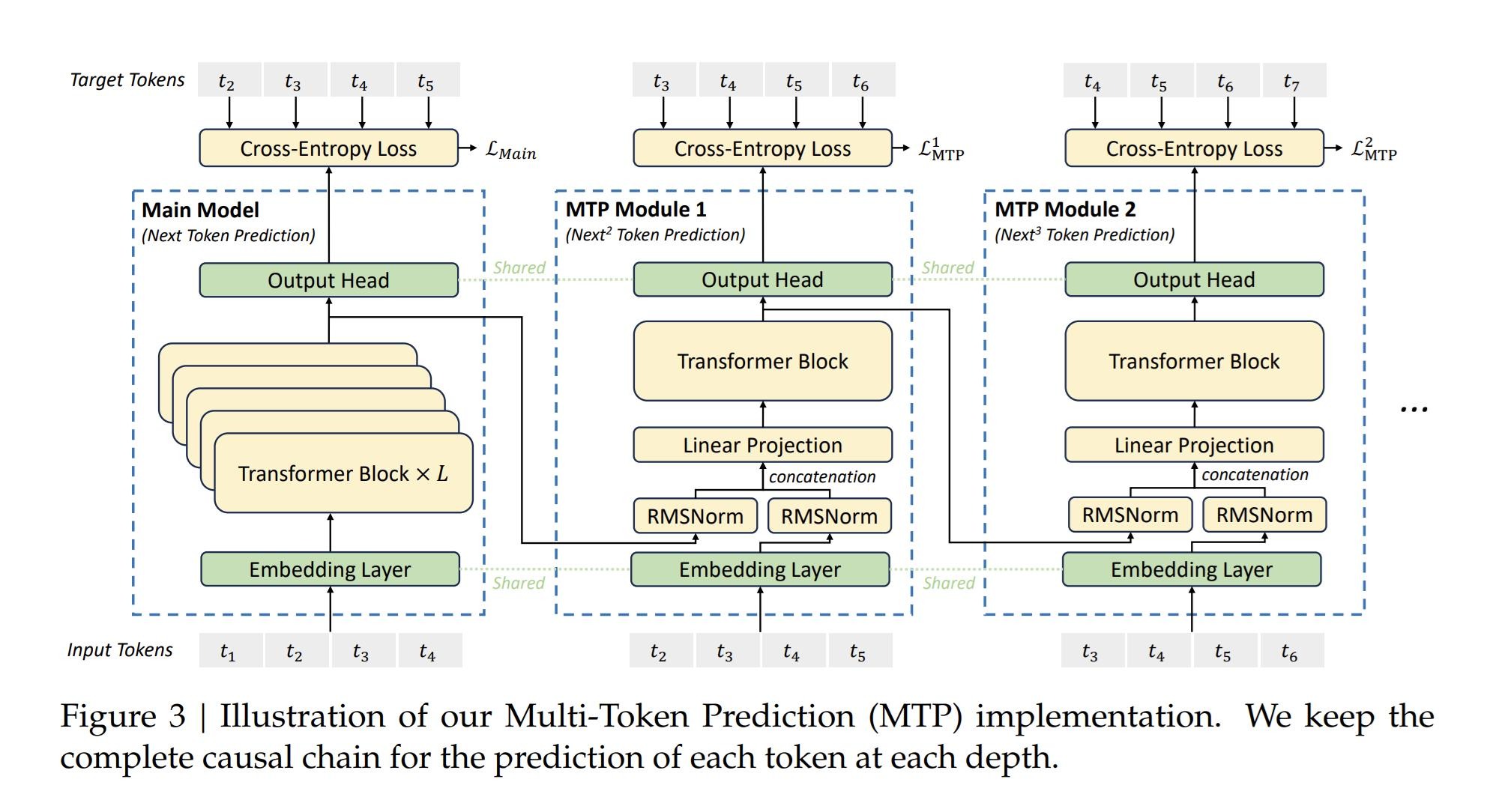
范式2:DeepSeek级联因果MTP
DeepSeek改良核心:MTP模块串行级联,严格保留因果生成链,解决连贯性问题(主流配置:2~3层MTP模块,一次性预猜后续2~3个token)。
1. 层级结构
- Main主干:完整Transformer,输出hidden_state,主输出头做标准$t+1$预测(原生NTP);
- MTP₁模块:输入=主干最后一层隐特征 + 真实$t+1$token的Embedding → 经过小型Transformer块 → 预测$t+2$;
- MTP₂模块:输入=MTP₁输出隐特征 + 真实$t+2$token的Embedding → 预测$t+3$;
规律:第$k$层MTP依赖前一层输出+对应真实token嵌入,严格自回归因果,和真实文本生成逻辑一致。
2. 参数复用
- 所有MTP模块共享输入Embedding层、共享最后的Unembedding输出头,仅内部少量线性/Transformer块为新增参数;
- MTP单块参数量远小于主干(主干67B,单MTP仅数亿参数),新增参数量≤5%总参数量。
3. 损失函数设计
\(\mathcal L_{total}=\mathcal L_{main}+\sum_{k=1}^n w_k\cdot\mathcal L_{mtp,k}\)
- $\mathcal L_{main}$:主干标准单token交叉熵损失(权重最高);
- $w_k$:深度加权系数,浅层MTP权重偏高、深层逐步衰减,优先优化近未来token,DeepSeek采用Sigmoid自适应加权;
- 全部MTP损失一起参与梯度回传,稠密化监督信号。
三、训练阶段收益
- 稠密监督,样本利用率翻倍 单个位置特征不再仅预测1个label,1个hidden同时参与$n+1$次预测(1主+n辅),同等数据量训练效果显著提升,长文本、推理、代码任务涨幅最明显;
- 强制模型学习远期规划表征 模型必须在当前上下文编码里嵌入$t+2、t+3$语义信息,天生增强长距离依赖、多步推理能力,解决NTP短视问题;
- 预训练+微调双受益:同参数量模型加MTP后,MATH、GSM8K、代码评测普遍+2~5个点。
四、推理阶段:MTP=原生Speculative Draft(投机解码草稿器)
标准MTP解码全流程(核心提速逻辑)
1次主模型前向=校验N个token,大幅减少主干Transformer前向次数
- Draft草稿生成(轻量MTP) 主干算出$T_{out}$(第一个正式token)→ 丢弃主干,仅用级联MTP快速串行生成后续$T_{out+1},T_{out+2}$(2~3个草稿token),MTP算力仅为主干1/10以内,耗时可忽略;
- Verify并行校验(主模型单次前向) 把「正式token+全部草稿序列」拼在一起送入完整主干模型1次前向,并行逐个校验每个草稿token概率:
- 匹配:直接保留、跳过本轮主干解码;
- 不匹配:截断序列,以第一个出错位置为新起点;
- 循环迭代:一轮解码一次性吃下2~3个有效token,相比原生逐一生成,吞吐量提升1.7~2.8倍,草稿通过率DeepSeek可达85%~92%(远高于小模型草稿65%~75%)。
关键优势对比普通小模型投机解码
- 普通Speculative:单独训小Draft模型,数据分布和主模型不一致,校验通过率低;
- MTP-Draft:和主模型同数据联合预训练,表征同源,草稿分布高度贴合主模型,通过率高、提速稳定,vLLM/SGLang/TensorRT-LLM全框架原生支持MTP加速。
五、MTP、MLA、MoE协同(DeepSeek-V3完整技术栈)
你前面学的MLA(KV低秩压缩)+MoE混合专家+MTP多Token预测构成DeepSeek三大核心优化: |技术|优化方向|落地作用| |—-|—-|—-| |MLA|注意力KV显存压缩|大幅降低KV Cache占用,超长上下文省显存| |MTP|训练稠密监督+推理投机加速|提升模型精度+解码吞吐×2~3| |MoE|稀疏专家激活|训练/推理算力节约,大参数量低成本部署|
三者叠加:同等GPU显存,上下文更长、生成更快、效果更强,是当前超长上下文LLM最优架构组合。
六、MTP优缺点汇总
✅优点
- 性能增益:训练增强推理/长文本能力,数学、代码、长文档显著涨分;
- 推理提速:零额外模型,原生Draft,加速稳定无质量损失;
- 兼容性:可叠加PagedAttention、KV量化、MLA,收益相乘;
- 部署友好:推理不想加速时可直接丢弃全部MTP模块,变回原生NTP模型,权重无损。
❌缺点
- 训练开销小幅上涨:新增MTP模块+多损失,训练FLOPs+5%~10%;
- 级联MTP实现复杂:因果串联+Embedding残差融合,算子定制成本高于Meta并行MTP;
- 短文本收益有限:生成≤512token短句,加速提升不明显,长文本(>4K)收益爆炸。
text 这篇文章很好