Multi-Head Attention
Multi-Head Attention(多头注意力)是 Transformer 的核心组件之一,将查询、键、值分别投影到多个子空间(头),在每个子空间中独立计算注意力,最后拼接起来。
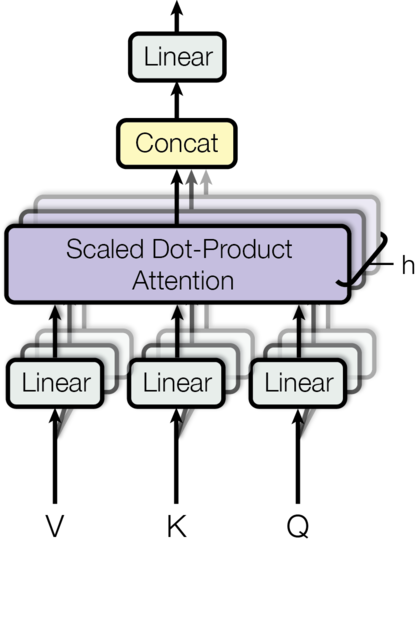
工作原理
输入
│
├──→ 头1: Q₁K₁V₁ → Attention₁ ──┐
├──→ 头2: Q₂K₂V₂ → Attention₂ ──┤
├──→ 头3: Q₃K₃V₃ → Attention₃ ──┤── 拼接 → 线性变换 → 输出
└──→ ... │
每个头学习关注不同类型的模式:
- 某些头关注语法关系
- 某些头关注语义相似性
- 某些头关注位置邻近性
优势
- 多角度:从不同表示子空间同时关注信息
- 互补:各头的关注模式互补,信息更丰富
- 可扩展:增加头数可以提升模型容量